




Originally written by Carlos Padilla.
Introduction
Medusa is an open source headless commerce that allows you to build digital commerce through its API with just a few commands and in a matter of time. You can host Medusa’s server on any of your preferred hosting choices, and one way to host it is using AWS Elastic Beanstalk.
AWS Elastic Beanstalk is a service for deploying and scaling web applications and services developed with many programming languages and frameworks including Node.js.
Through this guide, you will learn how to create a simple pipeline with AWS CodePipeline that pulls your Medusa’s server code from a GitHub repository and automatically deploy it to AWS Elastic Beanstalk.
Why Elastic Beanstalk?
Using Elastic Beanstalk you will be able to deploy a Medusa server application within the AWS Cloud. You just deploy your application and Elastic Beanstalk mechanically handles the main points of capability provisioning, load equalization, scaling and application health observance.
Once you deploy your application, Elastic Beanstalk builds the chosen supported platform version and provisions all the AWS resources like AmazonEC2 instances or Databases that your application needs to run.
So, in a nutshell, AWS Elastic Beanstalk makes it easy for developers to deploy their applications and share them with the world.
Prerequisites
To follow along with this tutorial you need the following:
- A working Medusa server application. You can follow the quickstart guide to get started.
- A GitHub account.
- An AWS Account with an IAM user, you can check here how to create one. Be sure your IAM user has the sufficient permissions to interact with Elastic Beanstalk, you can check more info about that here.
Set up a Node environment on Elastic Beanstalk
The first step is to create a Node.js environment on Elastic Beanstalk with a sample application. Later on you’ll replace the sample app with the Medusa server.
Go to AWS sign in page and login with your IAM user. You’ll be redirected to the Console Home page.
Once you are here, go to the top search bar and write Elastic Beanstalk; in the results choose the first option.
That will lead you to AWS Elastic Beanstalk Dashboard page, where you will have to click on the Create application button.

You can use “Create Web app” console wizard to create your sample application.
- Specify your Elastic Beanstalk application name information, for this tutorial the name is
aws-medusa-server. - Click on Platform drop-down and select the Node.js platform. At the time this article was written, the platform branch selected was
Node.js 16 running on 64bit Amazon Linux 2, and the platform version was5.5.0. - Select the Sample Application as application code.
- Click on Configure more options and go to the Capacity section. Once you are there click on edit.
- On the Modify capacity page go to instances types and choose
t2.smallandt2.medium, then click on save.
This step is very important because by default the instances type are
t2.microandt2.small, however themicroinstance has only 1 Gb of RAM. This is enough for testing and development, but we recommend going with a larger instance for a production environment.
- Back in the Configure more options page, go to the Database section and click on edit. Here you are going to set up the PostgreSQL database needed for the medusa server. The suggested configuration is to choose postgres as engine with version 10, 11 or 12. You’ll also need to enter a username and password. Make sure to save those for later as you’ll use them. Once you’re done, click on Save.
- Last, click on “Create App“ button. It will take few minutes to launch your application.
Once the environment is created you can go to the overview page and check Environment Health, application running version and application platform version where application is running on.
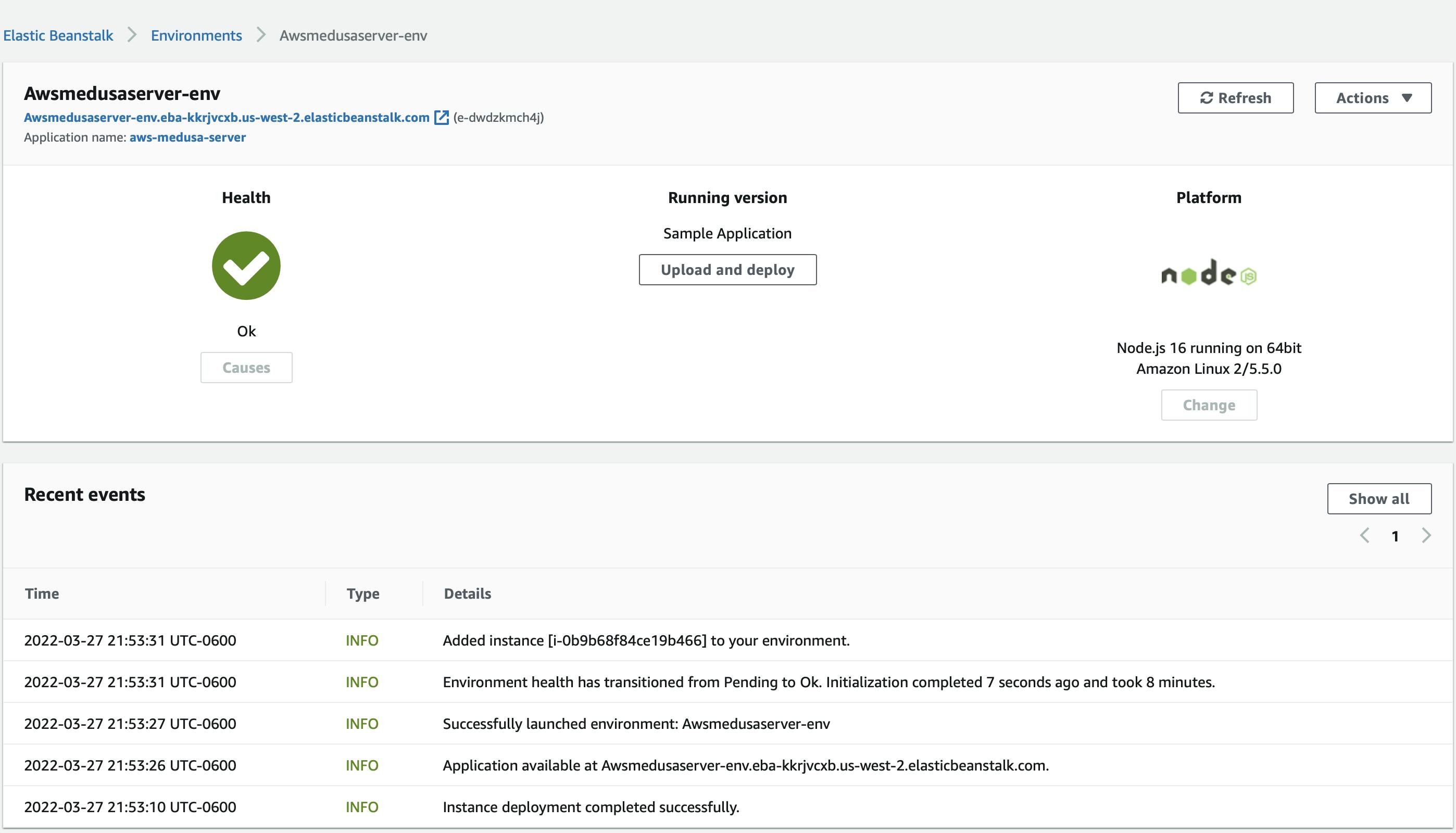
On top of this page you will see the environment’s URL below the environment name, click on this URL to get to the sample application’s congratulations page.

Until this point you should have a Node environment running on AWS Elastic Beanstalk with a sample application, the next step is to prepare the medusa server to be deploy on this environment.
Preparing Medusa server
To create the pipeline for CI/CD you need to do some changes on your medusa server repository and push them to GitHub.
First, in your Medusa server, open your package.json file and add the following property at the end
"engines": {
"node": ">=16.0.0"
}
Be careful: the node version must match the version that you set when creating the environment. AWS Elastic Beanstalk will search for this before deploying your app with AWS CodePipeline, so, if you don’t do this, then the deployment will fail.
In this file, you also need to change the start command to the following:
"start": "medusa migrations run && medusa develop -p=8080",
Basically, what you are doing is changing the port on which the medusa server run by default, so, instead of running on port 9000 it will run on port 8080. The main reason to do this is because by default AWS Beanstalk run ngix as reverse proxy to redirect all the incoming traffic from the internet on port 80 to port 8080.
Also, it is necessary to run migrations on the server before running the Medusa server.
The next step is to add a Procfile to the root of your project with the next line of code
web: npm run start
This instructs AWS Beanstalk on how to run your application once all the dependencies are installed with npm install, first it will run the medusa migrations, and then it will start the app.
The last thing you need to do is make sure you’ve set your Database to use PostgreSQL. In medusa-config.js, make the following changes in the exported object:
database_url: DATABASE_URL,
atabase_type: "postgres",
// database_database: "./medusa-db.sql",
// database_type: "sqlite",
When all these changes are done, commit and push them to your remote repository on GitHub.
Once the repository is ready on GitHub, the next step is to create an AWS CodePipeline.
Add environment properties
To create the pipeline, you need to set some environment variables on your node environment on AWS Beanstalk. This is because when you finish setting up the code pipeline, it will be triggered immediately and it will do the first deployment. So, to get an OK status all the env variables needed by the Medusa server need to be set in advance.
On the overview page of AWS Beanstalk, go to the left pane and search for the Configuration menu of your node environment and click on it.
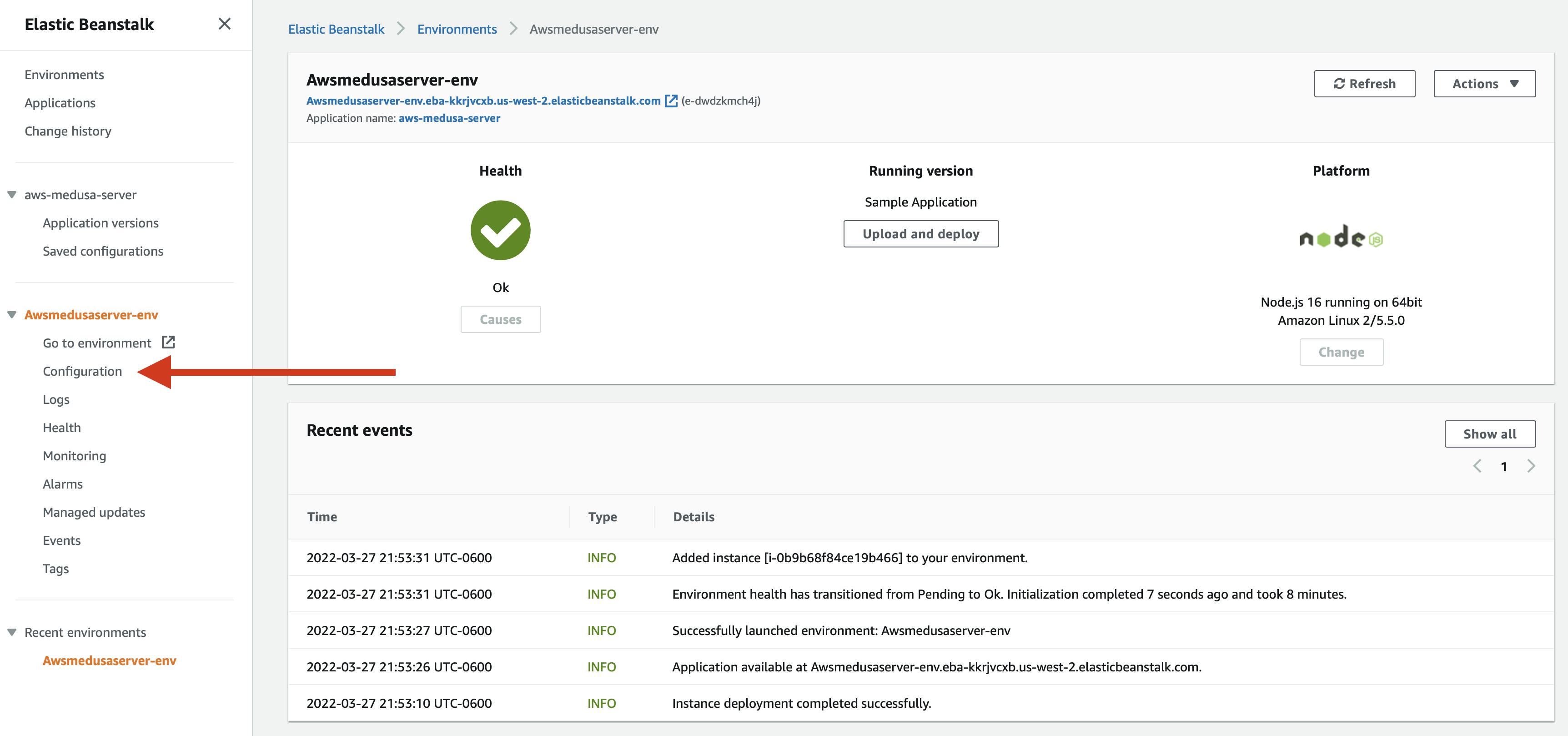
Then click on the Edit button next to Software.
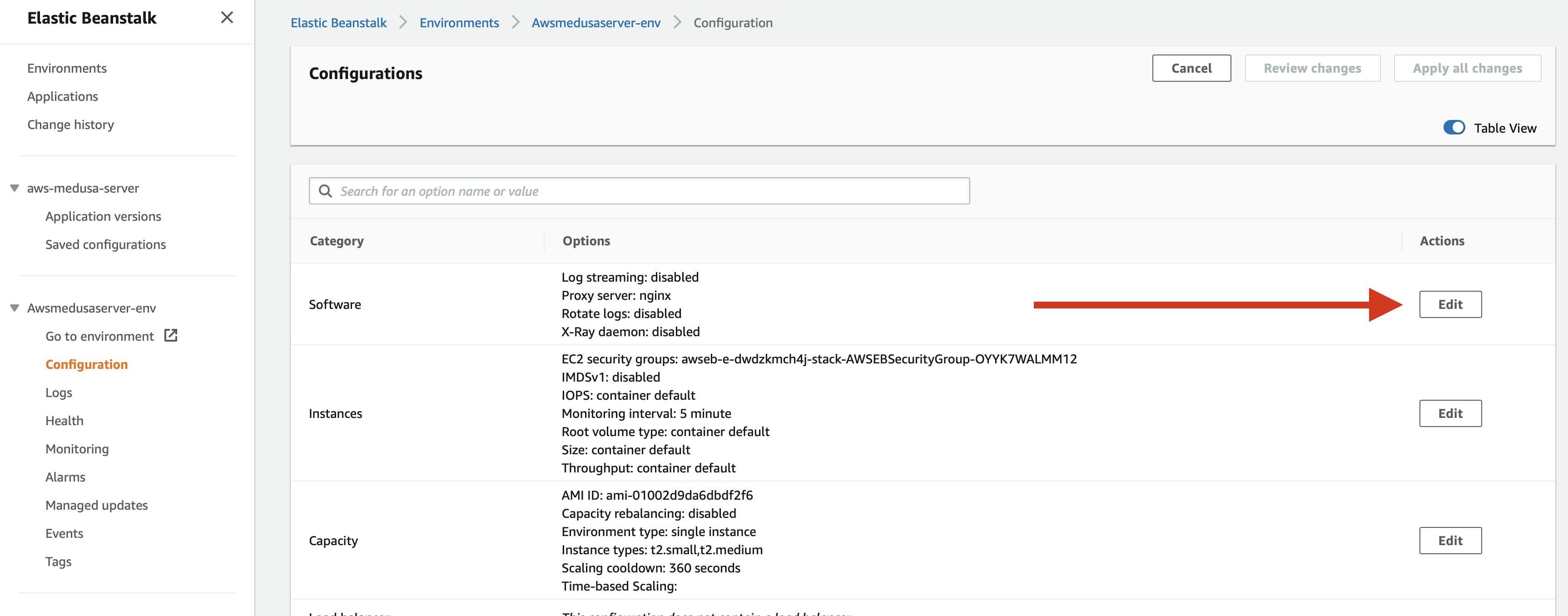
In the Modify software page go to the last section called Environment properties and add the following properties
NPM_USE_PRODUCTION=false
JWT_SECRET=something
COOKIE_SECRET=something
DATABASE_URL=postgres://<<USERNAME>>:<<PASSWORD>>@<<DATABASE_URL>>:5432/<<DB_NAME>>
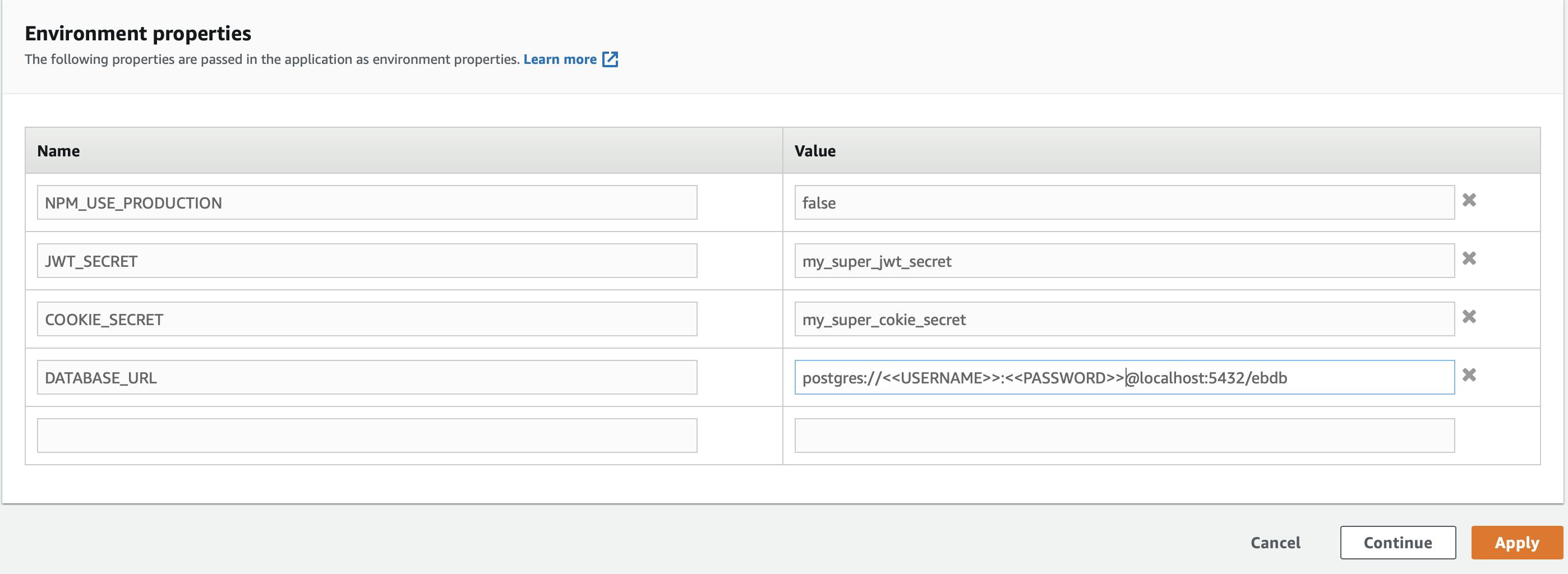
Pay special attention to the first and last properties. The first property is to allow AWS Beanstalk to install the dependencies (babel) needed to run the command medusa develop.
The last one is the URL to connect to the database. Here, you need to change <<USERNAME> and <<PASSWORD>> with the ones you set when creating the node environment.
As for <<DB_NAME>> and <<DB_URL>> you can find those by searching for “RDS” in your AWS Console. Then click on Databases in the sidebar. You should see a PostgreSQL database.
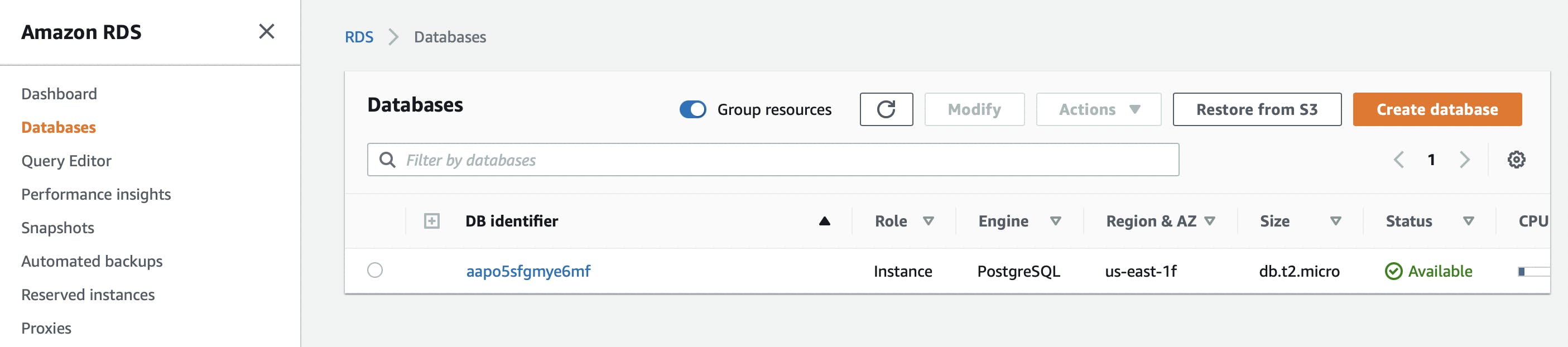
Click on the DB identifier and scroll down to Connectivity & Security. The URL under Endpoint is your <<DB_URL>>. As for <<DB_NAME>> , you can find it under the Configuration tab. By default, it’s ebdb.
After adding the environment variables, click on Apply and wait until the environment is updated with this changes. Once the update is complete, you can now go on and create the CodePipeline.
Set up AWS CodePipeline
The goal of the pipeline is to listen for changes or commits on the main branch of your Medusa server’s repository on GitHub. When this happen the pipeline will be triggered and it will starts a new deployment to update your application on AWS Beanstalk.
Make sure that before continuing with this step you’ve created a repository for your Medusa server.
Go to the top search bar and write CodePipeline in the results choose the first option
On CodePipeline dashboard page click on the button “Create Pipeline”.
Make sure that your are in the same region where is your node environment.
On the Choose pipeline settings page, give a name to the pipeline and leave everything as it is and click on the Next button. For this tutorial, the name will be aws-medusa-server-pipeline.
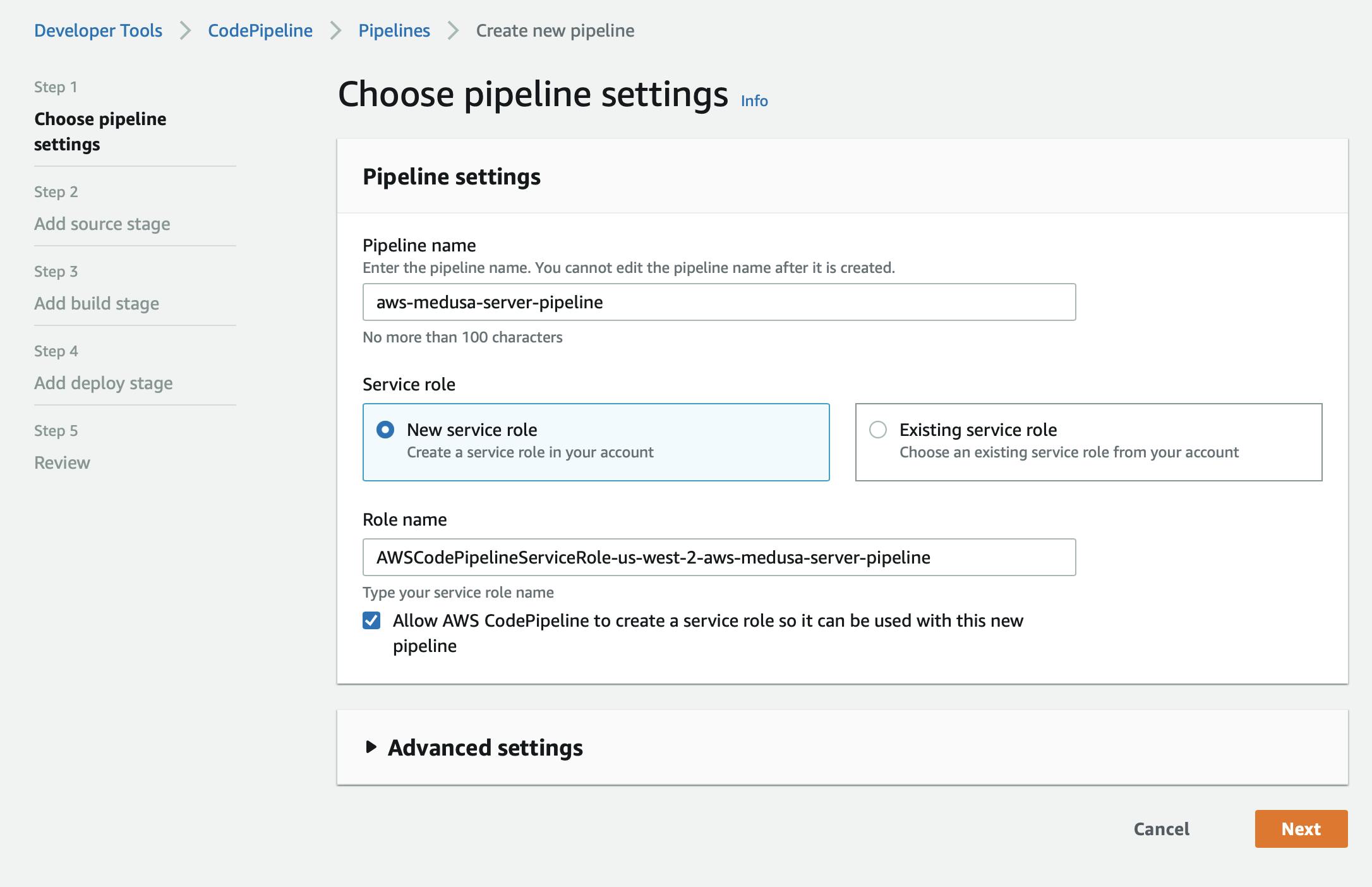
On the Add source stage page, under Source Provider dropdown choose GitHub (Version 2). Then, If you have not created a GitHub connection, click on “Connect to GitHub” button to grant permission to AWS CodePipeline to access your Medusa server repository on GitHub. This will help AWS Code Pipeline to upload your committed changes from GitHub to AWS CodePipeline.
Once you’ve connected GitHub, choose your repository and the branch from where you will be pulling your application.
Check the option that says Start the pipeline on source code change and for the Output artifact format option choose “CodePipeline default”. Click on the Next button.
On the Add build stage page, you will click on the Skip build stage button.
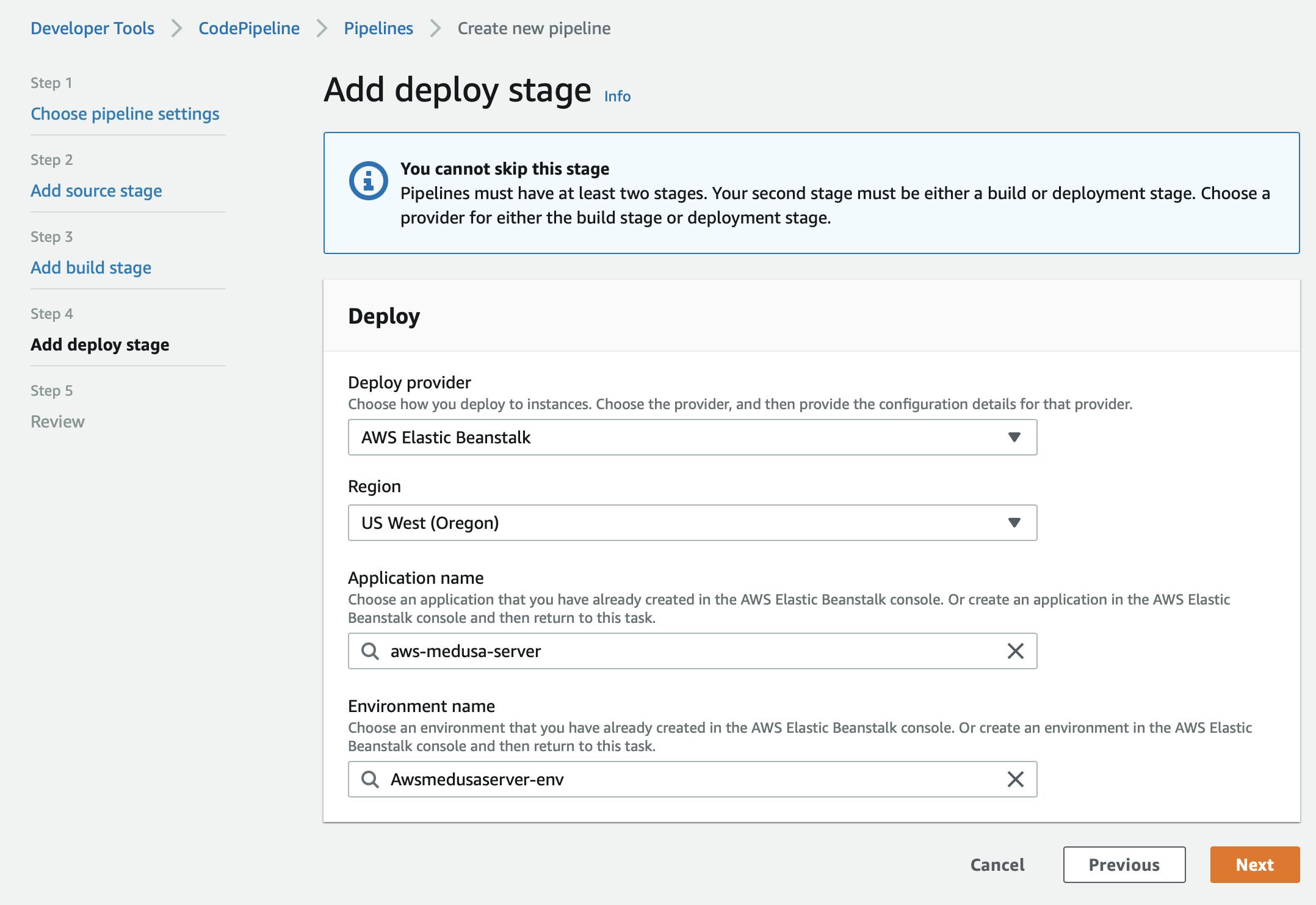
On the Add deploy stage page, under Deploy provider dropdown, select “AWS Elastic Beanstalk”, then choose the region your node environment is in and the application and environment you created earlier (in the case of this tutorial these are aws-medusa-server and Awsmedusaserver-env respectively) Once you’re done, click on the Next button.
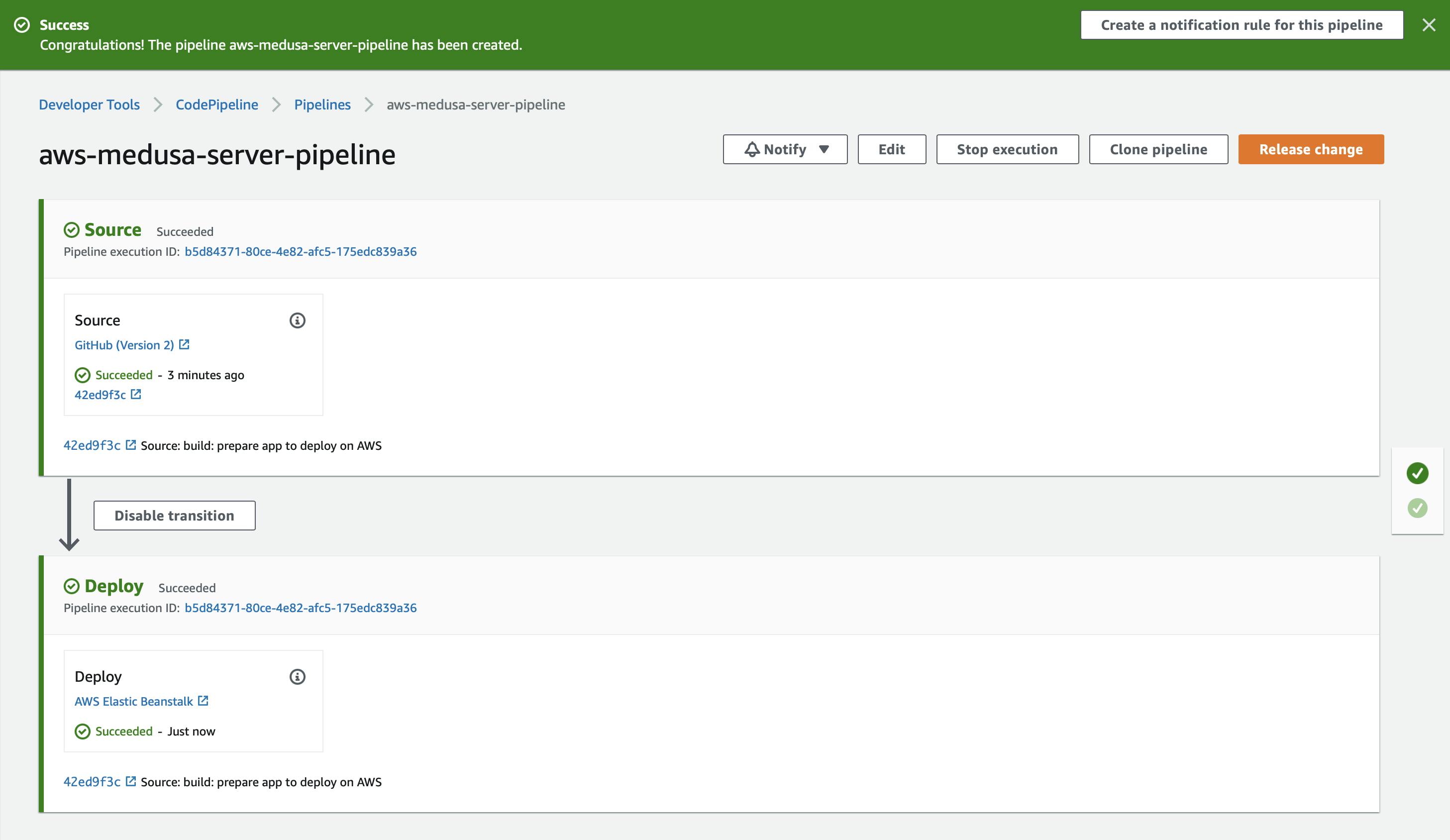
On the Review page, check that everything is fine. Then, click on the Create pipeline button.
You will see a success message banner displayed, and the pipeline actions will be running until they are completed. If everything went fine, both stages will be mark with a checkmark success.
Test it Out
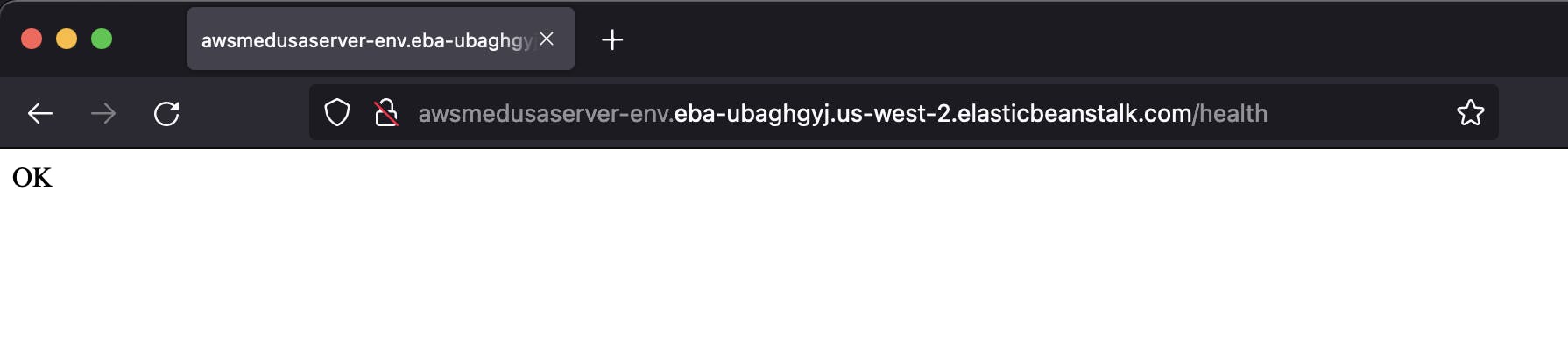
To check that your Medusa server is working, go back to the Elastic Beanstalk dashboard and search for the environment’s URL below the environment name, then do the following:
- Copy the URL.
- Open a new tab in your browser, paste the URL and add at the final
/health, so the URL would something like this:
http://awsmedusaserver-env.eba-kkrjvcxb.us-west-2.elasticbeanstalk.com/health
You should get an OK message, if that is the case, then you have successfully deployed your Medusa server into AWS Elastic Beanstalk.
Make sure to change the URL in your Medusa storefront or admin based on the URL of your server.
Troubleshooting
If you run into any issues or there’s a problem with your deployed server, you can check the logs in your Elastic Beanstalk instance by clicking on Logs in the sidebar.
Conclusion
Deploying a Medusa server on AWS Elastic Beanstalk is easier with the help of CI/CD pipelines. Once you’re done, you can focus on adding new functionality to your Medusa server as custom endpoints, services or plugins.
Then, to push the changes to your server you can just push them to your GitHub repository. The configured pipeline will detect changes and start execution. Your application will then be updated with the new features.
To learn more about how to customize your store or how you can connect a storefront to your store, be sure to check out Medusa’s documentation.
If you have any issues or questions related to Medusa, then feel free to reach out to the Medusa team via Discord.